Understanding hands and the objects they interact with, both directly and through tools,
is a key step for tasks ranging from action perception to 3D reconstruction and robotics.
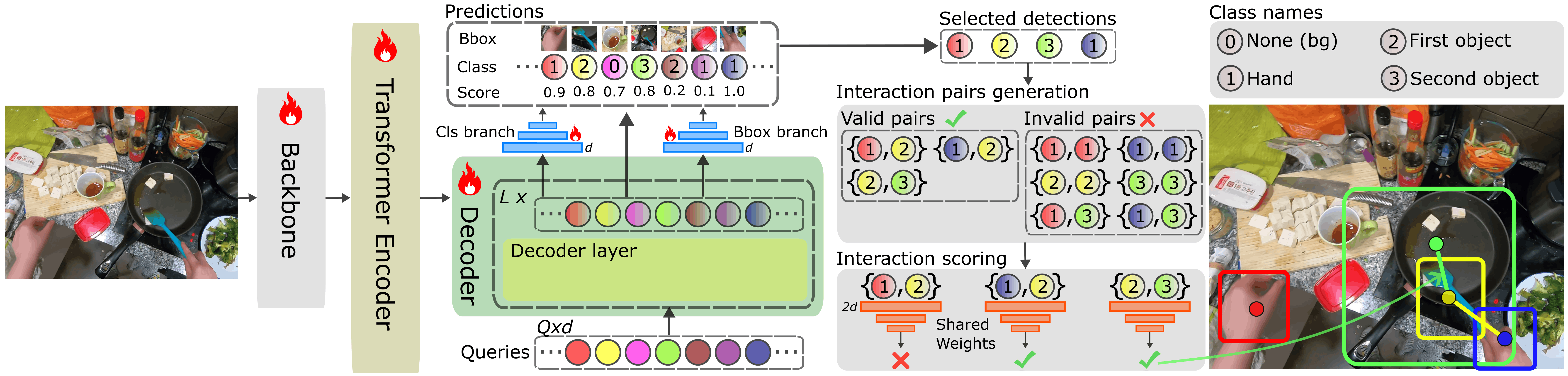
We introduce HOI-DETR, a new framework that integrates hand-object and
object-object interaction into the Co-DETR architecture, producing a method that jointly
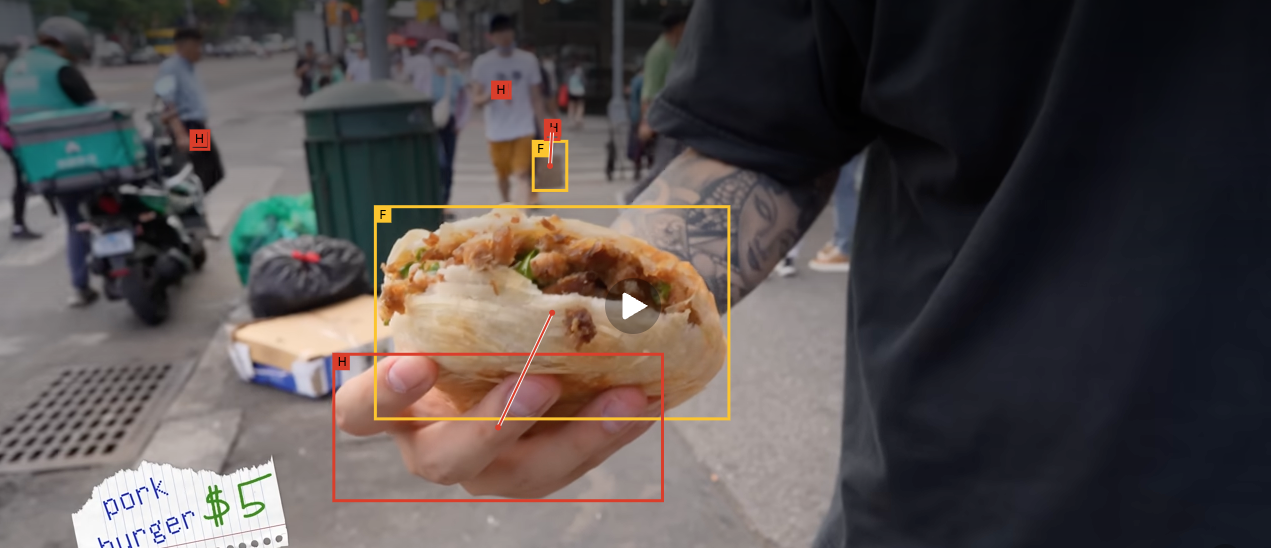
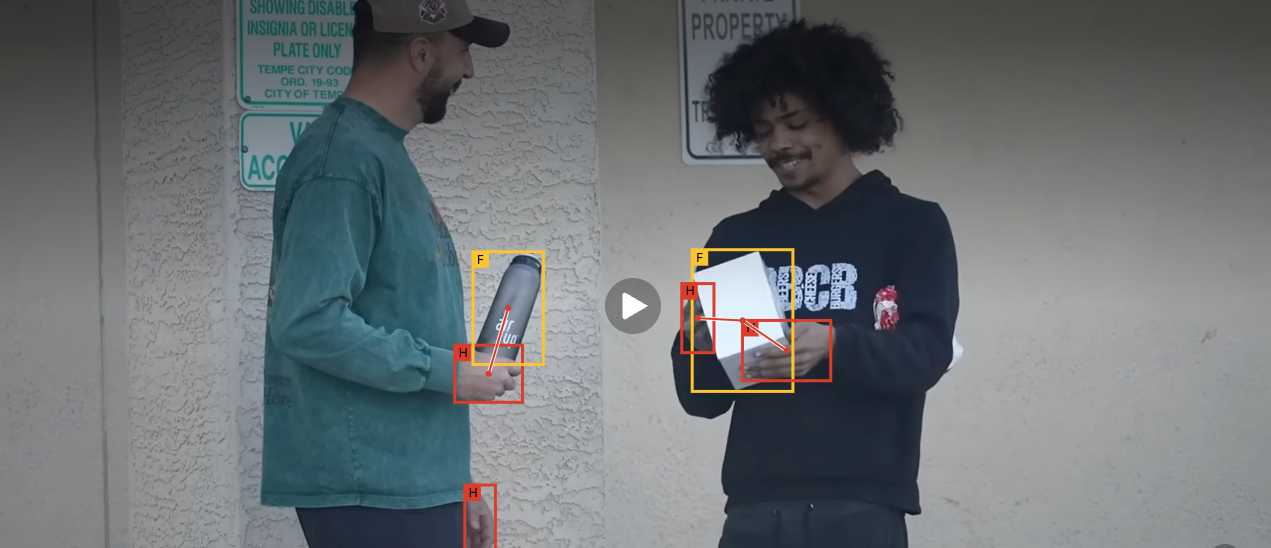
detects all visible hands,
1st objects (objects in direct physical interaction with a hand), and
2nd objects (objects that the 1st object acts upon when used as a tool),
and predicts their pairwise interaction links in a single forward pass.
We accompany the model with a comprehensive HOI evaluation suite spanning four diverse
datasets, including a new video benchmark derived from the HD-EPIC dataset and refined
annotations for the Hands23 benchmark. HOI-DETR significantly improves over the previous
state of the art, with mAP gains of over 20 percentage points, and demonstrates strong
zero-shot generalisation to unseen datasets and domains.